高质量数据集典型案例 | 数字教育应用算法智能诊断公共数据集
- 2025.09.15
- 来源:国家数据局
数字教育应用算法智能诊断公共数据集
推荐单位:教育部申报单位:北京师范大学、中国信息通信研究院
一、背景
本数据集聚焦教育数字化转型背景下教育智能算法的可测、可控与可治理问题,构建了国内首个面向典型教育场景的“数字教育应用算法智能诊断公共数据集”。数据集按全耦合型、圈层拓展型等5类算法结构组织,覆盖3000个开源算法、150组试测数据及多任务标注样本,支撑教学诊断、学情预警、治理效能、资源评估、科学研究、认知发展等数字教育产品在线典型场景中的育人科学性监测。
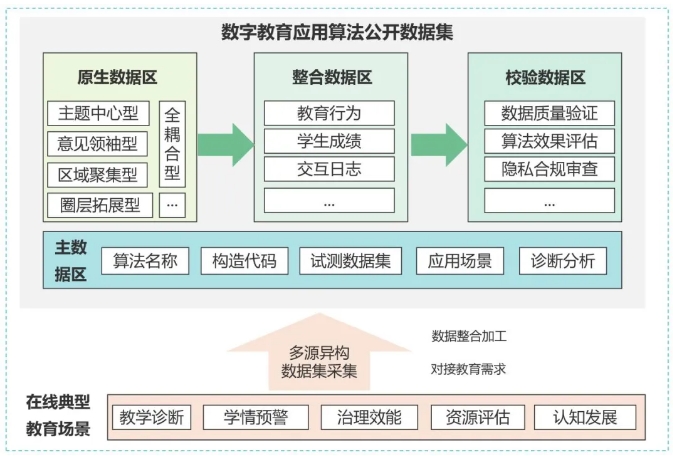
数字教育应用算法智能诊断公共数据集构建图
二、方案和成效一是构建三级数据区与算法机制,强化多方协作与智能诊断。设立“原生—整合—校验”三级数据区架构,创新算法全生命周期记录与任务驱动建模机制,强化隐私治理与开放共享。目前已与10所高校、数百家企业开展算法研发测评,并在241所学校的在线学习环境中进行算法活动追踪智能诊断,对“训练集数据过拟合/欠拟合”“测试集轮次优化逻辑”“推理场景契合度”等维度进行多维度对比诊断。
二是完成首批原型数据集建设,打通研发全链路通道。建成覆盖全耦合型等五类核心算法模型的400个开源算法构造包,开放150组试测数据集与代码实例,实现数据底座至应用任务的全链路打通,形成可直接调用的标注样本集,极大降低了教育算法研发门槛。
三是实现显著经济效益,挖掘数字教育市场潜力。试运行期间节省算法调测成本30%,面向2025年中国数字教育超万亿市场中500亿~800亿元风险监测需求,在占比不低于25%的算法领域形成重要服务能力。
四是规划规模化发展与国际合作,打造行业标杆。计划2025年形成3500个总体规模,专注教育数字化领域,目标成为国内规模第一、国际同领域前列的算法公开数据集。同步推进与欧洲、东南亚高校合作共建,提升数据集规模并扩大开放服务范围。
三、创新点
一是范式先进性。数据集以AI4S的第五范式为基础,综合经验、理论、计算和数据前四代范式优势,突出“数据要素+算法驱动+算力支撑”的协同动态开源特点,实现算法名称、构造代码、测试数据集、应用场景、诊断分析全链对接。
二是运营成熟性。该数据集是科技部国家重点研发计划项目的成果之一,自试运营以来,已与10余所高校、20余家数据标注基地、数百家企业开展算法研发与测评合作,为240余所学校在线学习环境中完成算法活动追踪智能诊断。
三是共享推广性。构建了可扩展、可复用的算法诊断资源体系,支持跨机构、跨平台的数据共享与算法比对。秉承跨界共研、确权共享原则,北京师范大学牵头,联合产学研各界共同服务“教学管评研育”场景。
- 附件: