数据标注优秀案例集之二十五 | 多模态数据自动化标注与增强平台
- 2025.06.01
- 来源:国家数据局
- [ 打印 ]
多模态数据自动化标注与增强平台
申报单位:中电万维信息技术有限责任公司推荐单位:甘肃省发展和改革委员会
一、案例简介
针对高质量数据稀缺且样本不均衡等问题,中电万维信息技术有限责任公司依托算力、数据、模型及人才优势,积极打造数据标注中心,构建多模态数据自动化标注与增强平台,通过智能算法与自动化流程,实现多模态数据的快速精准标注,数据标注效率提升200%。已累计完成200多万条高精度标注数据,覆盖工业、农业、政务、办公等多个领域,为企业数字化转型提供高质量数据支撑,显著推动产业智能化升级。
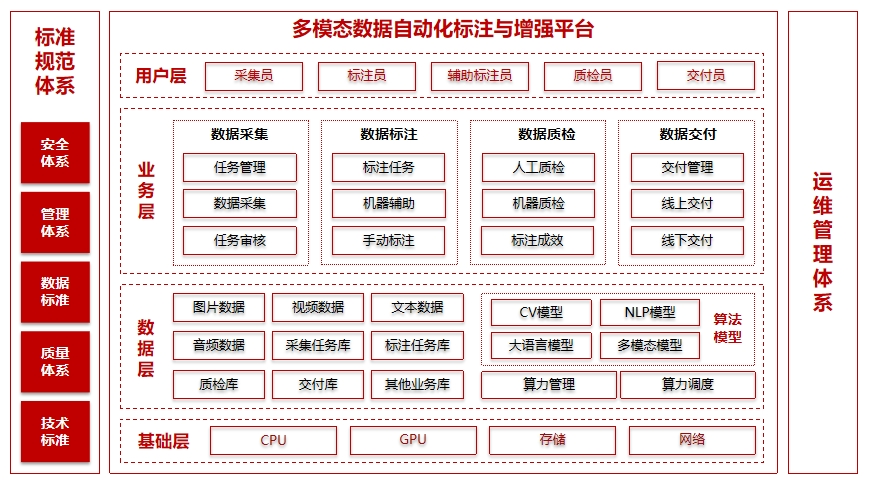
整体框架
二、举措与成效一是多模态数据自动化标注。针对多模态数据标注需求,构建高精度的辅助标注模型,基于该模型实现交互式标注与批量预标注等能力,显著提升了标注效率,确保高质量的多模态数据标注结果,为多模态数据的规模化处理和精细化分析提供支持。
二是文本数据自动化合成。针对文本数据处理需求,平台深度融合大语言模型的语义理解与生成能力,构建多层级的自动化标注与智能扩充方案,通过上下文感知、实体关系挖掘及迁移学习技术,使其能够更精准地适应特定场景的标注任务,显著提升数据标注的效率和质量。
三是稀缺数据多样化增强。针对数据稀缺及样本不均衡问题,通过算法或人工干预对原始数据进行多样化数据增强处理,包括翻转、旋转、缩放、平移、裁剪、颜色变换、噪声添加、模糊和仿射变换等,提高数据的多样性,进一步提升模型泛化能力。
三、特色亮点
一是多模态长尾目标的自动化标注能力。平台依托辅助标注模型,通过整合类别语义、目标特征及空间位置信息,自动生成目标框与像素级标注,同步提升标注效率与精度。针对长尾分布问题,结合预训练模型的泛化优势与小样本迁移学习策略,有效增强长尾目标的识别覆盖率与标注稳定性。
二是基于蒸馏技术提升文本数据标注效率。平台基于知识蒸馏框架,将大模型自监督学习能力迁移至轻量化标注引擎,通过任务自适应蒸馏机制实现标注流程智能化,降低约90%人工标注介入需求。创新集成文本生成蒸馏技术,运用师生模型协同优化策略,同步完成数据自动化扩增与语义保真校验,标注效率提升3倍以上。
- 附件: