数据标注优秀案例集之三十 | 矿山数工—数据标注赋能矿山行业高质量发展
- 2025.06.06
- 来源:国家数据局
- [ 打印 ]
矿山数工—数据标注赋能矿山行业高质量发展
申报单位:煤炭科学研究总院有限公司推荐单位:北京市政务服务和数据管理局
一、案例简介
针对矿山行业数据标注标准缺失、多模态数据标注成本高、海量数据价值释放困难等困境,通过构建矿山行业知识标签体系、多模态数据生成算法与合规校验模型等,实现标注效率提升30%,跨模态语义一致性优化20%,高质量数据复用率提升50%,将行业人工智能应用研发周期由3个月缩短至3周,支撑矿山百通、矿山视巡等系列应用建设,为行业高质量发展提供核心引擎。
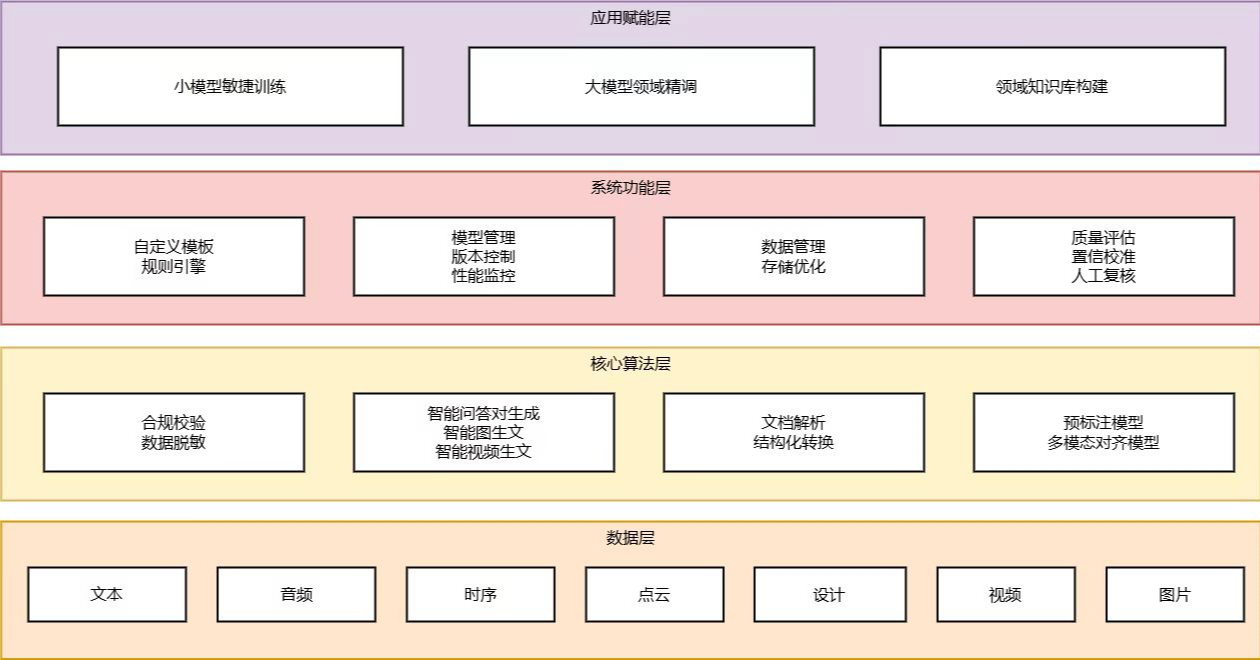
整体框架
二、举措与成效一是标注标准化,建立场景级标签体系,提升标注效率。针对矿山数据标注繁杂低效的问题,依托行业标签体系,研发适配矿山场景的海量标注模板,融合7大模态数据,赋能小模型敏捷训练。实现500亿传感数据、300万视频数据、200亿词元文本数据的统一标注,跨模态数据标注处理效率提升30%,跨模态语义一致性优化20%,有效降低标注成本。
二是生成智能化,合成高质量微调数据,攻克长尾困境。为增强行业理解能力,依托太阳石矿山大模型,突破跨模态语义增强技术,构建行业问答对自动生成机制。实现行业大模型微调数据的自动合成,减轻问答对构建70%耗时,提升大模型行业词汇理解力8%,助力太阳石矿山大模型对矿山行业法规遵循能力由84分优化至95.5分。
三是数据结构化,定期更新知识底座,释放数据价值。鉴于行业知识更新快、应用产品优化难,构建非结构化文本智能转换系统,研发合规校验模块,并以标签体系为依托构建行业知识库。实现行业标准、安全规程等数据的结构化存储与动态更新,使知识检索准确率提升至90%以上,并可快速迁移至其他应用,数据复用率提升50%,应用研发周期从3个月缩短至3周。
三、特色亮点
一是大小模型协同,破解数据标注瓶颈。利用行业大模型生成能力,有效扩充长尾场景数据量,解决行业数据稀缺性难题。经预标注小模型完成初筛标注与人机协同校验快速复核,生成高质量数据集,反哺大模型领域精调与小模型迭代,构建“生成-标注-训练-优化”闭环。
二是提升数据复用率,激活行业数据价值释放。覆盖多格式多场景数据格式化转换,支撑高质量数据集实现流程化、标准化构建,推动矿山经验从隐性知识向可量化资产转化。
三是行业数据赋能,共建可信应用生态。构建高质量场景数据集,为行业应用测评提供基准数据,降低验证主观性偏差,助力行业形成“知识共建、标准共享、生态共赢”可持续发展格局。
- 附件: