高质量数据集典型案例 | 石油化工领域高质量数据集
- 2025.09.23
- 来源:国家数据局
- [ 打印 ]
石油化工领域高质量数据集
推荐单位:国务院国资委申报单位:中国石油化工集团有限公司
一、背景
中国石化积累了大量数据资源,但存在多模态异构、标注专业性强、数据分散等特点。本案例旨在进一步整合内外部数据资源,构建一批多模态融合、行业代表性强的高质量数据集,突破跨模态对齐、自动清洗标注、动态质量保障及安全合规共享等挑战,为行业大模型训练提供高精度标注、多场景覆盖的高质量数据支撑,切实提升模型训练适配性与复杂场景泛化效能。
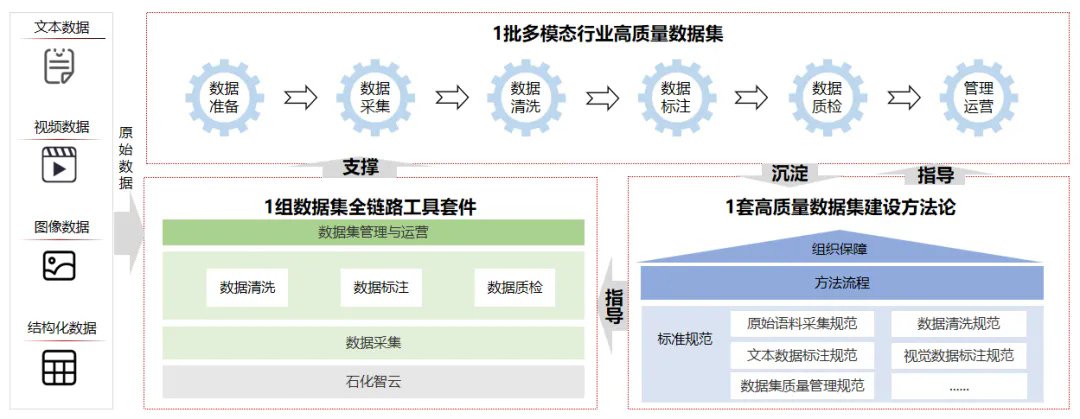
石油化工领域高质量数据集总体框架图
二、方案和成效一是构建1套行业级高质量数据集建设标准化方法体系。在实践基础上,提炼并形成了涵盖数据标准定义、质量评估指标、清洗标注流程规范、安全管控要求等全环节的石化行业方法论体系。
二是打造1组高质量数据集全链路工具套件。创新融合大语言模型(LLM)、多模态大模型,以及各类经训练微调的专业小模型与规则引擎,形成高质量多模态数据集的大规模工程化生产流程,提升数据集建设效率,保障智能化建设过程中数据高质、高效供给。
三是产生1批行业多模态高质量数据集。包括行业相关业务领域文件共近13万册,工业生产、安全等违章图片200余万张,厂区生产装置、作业现场等监控视频超500TB;生成高质量问答对超162万条。
四是支撑行业大模型训练和智能化应用。行业大模型专业能力明显提升。基于行业高质量数据集,完成第一版长城行业大模型(70B、700B)训练和应用,经工信部信通院、泰尔实验室评测,达到行业“引领级”;支撑分子理解、分子生成、不规范行为识别多模态、审计等专业大模型训练;大幅降低了从数据准备到模型训练的门槛,支撑1600余个智能应用在线开发。
三、创新点
一是自主研发智能化数据清洗标注工具链,突破工业数据治理瓶颈。实现复杂表格识别准确率85.71%,公式识别准确率91.67%,化学结构式识别准确率67.7%,系统性地解决了石化行业数据多源异构、专业性强、标注成本高等痛点。
二是首创“工具-数据集-场景”闭环赋能模式。打破数据建设与应用脱节的常规路径,创新性地建立了“工具建设-数据集生产-AI场景验证-反哺工具/数据集优化”的闭环赋能模式。
三是打造开放协同的高质量数据集共建共享生态。突破了传统企业数据内部封闭的局限,在保障数据主权与安全合规的前提下,创新性构建了由企业、科研院所、技术服务商共同参与的数据生态体系。
- 附件: