高质量数据集典型案例 | 面向人群复杂特征的高质量DNA甲基化数据集
- 2025.09.28
- 来源:国家数据局
- [ 打印 ]
面向人群复杂特征的高质量DNA甲基化数据集
推荐单位:中国科学院申报单位:中国科学院北京基因组研究所(国家生物信息中心)
一、背景
随着人工智能技术在生命科学领域的快速发展,DNA甲基化作为表观遗传的重要调控机制,正展现出巨大的临床应用潜力。相较于传统的遗传生物标志物,DNA甲基化在健康监测与预警、疾病早诊与分型、精准治疗与干预、预后预测与评估等方面表现出更优异的性能。当前DNA甲基化数据来源广、类型多、标准不统一,严重制约AI模型的训练效果和临床应用转化。国家生物信息中心建立涵盖近300类人群复杂特征、超18万标准化DNA甲基化图谱的高质量数据集,支撑AI赋能应用。
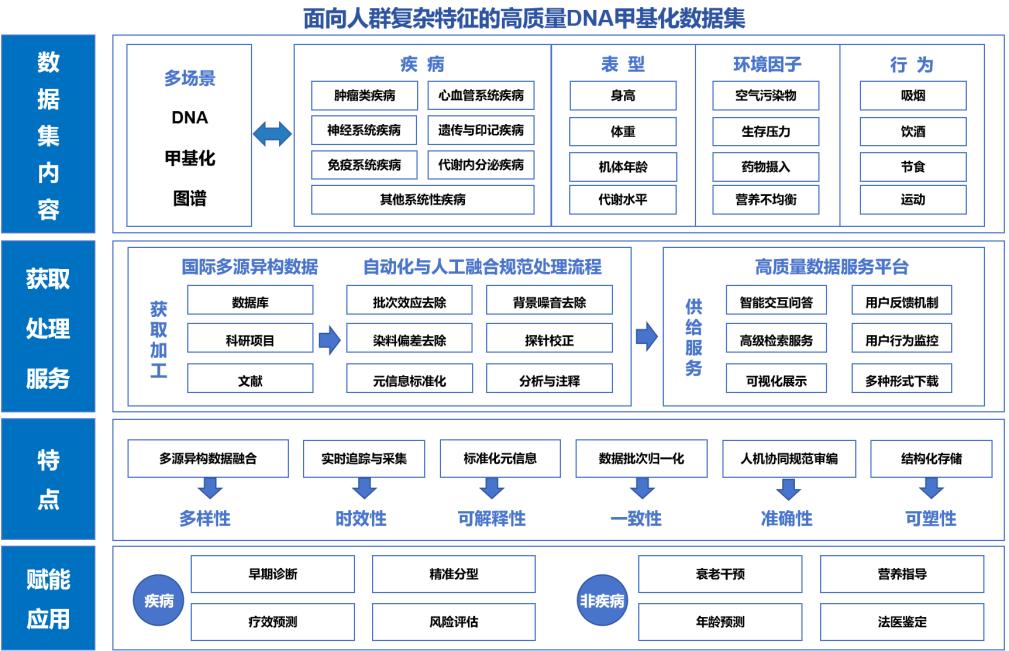
面向人群复杂特征的高质量DNA甲基化数据集概览
二、方案和成效一是建立多源多类DNA甲基化数据实时获取机制,确保采集全面性和及时性。建立多线并行的实时追踪和采集机制,实现对已发布DNA甲基化数据的自动化获取与整合,涵盖不同数据库、研究项目、文献的多来源信息,以及多种检测平台、数据格式和组织层级的多类型数据,有效应对多源异构数据的采集挑战,保障数据的多样性和可用性。
二是实现多源异构DNA甲基化数据标准化与协同校验,确保处理准确性和统一性。通过建立受控词表实现元信息标准化,制定统一的数据处理规范,并结合人机协同的数据校验与注释方式,突破数据异构和标准不统一等难题,保障多类型数据的准确性、完整性与可解释性。
三是构建智能更新与交互驱动的高质量DNA甲基化数据服务平台。建立高效的实时更新机制,确保数据保持时效性;完善用户反馈闭环体系,通过分析用户使用行为持续优化数据结构与服务模式;同时部署高级检索功能与多语种智能交互问答机器人,实现数据的智能推荐与精准推送,全面提升数据的获取效率与用户的服务体验。
三、创新点
一是破解大规模数据实时标准化难题。突破传统方法局限,构建校正参考信号,提出可分批处理的批次效应校正新方法。实现实时递增数据标准化,兼顾数据集的可扩展性与跨数据间的可比性,有效解决大规模累积数据持续标准化的核心难题。
二是打造AI赋能的多场景应用范式。围绕人口健康与疾病诊疗的关键需求,深度注释DNA甲基化数据,支撑健康监测、疾病早诊、精准治疗与预后预测等多场景AI模型训练。目前,该数据集已支撑国内外多个人口健康与疾病预测相关大模型的构建,这些模型在疾病与衰老预测、药物靶点识别任务中表现优异,并在数据缺失或质量不足的情况下仍保持稳定性能,大幅降低重复检测成本。
- 附件: