高质量数据集典型案例 | 中文互联网语料库系列数据集(CCI)
- 2025.10.10
- 来源:国家数据局
- [ 打印 ]
中文互联网语料库系列数据集(CCI)
推荐单位:北京市政务服务和数据管理局申报单位:北京智源人工智能研究院
一、背景
随着大语言模型的迅速发展,业界对海量、高质量、安全的数据集需求迫切。尤其在中文领域,高质量数据集严重短缺,且缺乏能提升模型推理能力(CoT)的数据。为应对此挑战,二十多家机构联合打造并开源了CCI系列数据集。作为中文领域最大规模的开源项目,CCI旨在建立覆盖多领域、多语言的高质量语料库(以中文为主),通过持续升级的质量标准和验证机制,推动大语言模型在下游任务及推理能力上的提升。目前,CCI系列已累计开源4个系列共7个数据集,数据总量约37T。
二、方案和成效
一是构建高效数据清洗与评估体系,提升语料纯净度与质量。我们融合多粒度去重与多分类器质量评分技术,前者通过SimHash与MinHash算法结合的双层级去重机制,实现了99.7%的重复内容识别率;后者利用知识蒸馏构建轻量化分类器,在保持超90%评分准确率的同时,将计算资源消耗降低至原方案的1/20,高效完成了亿级数据筛选。
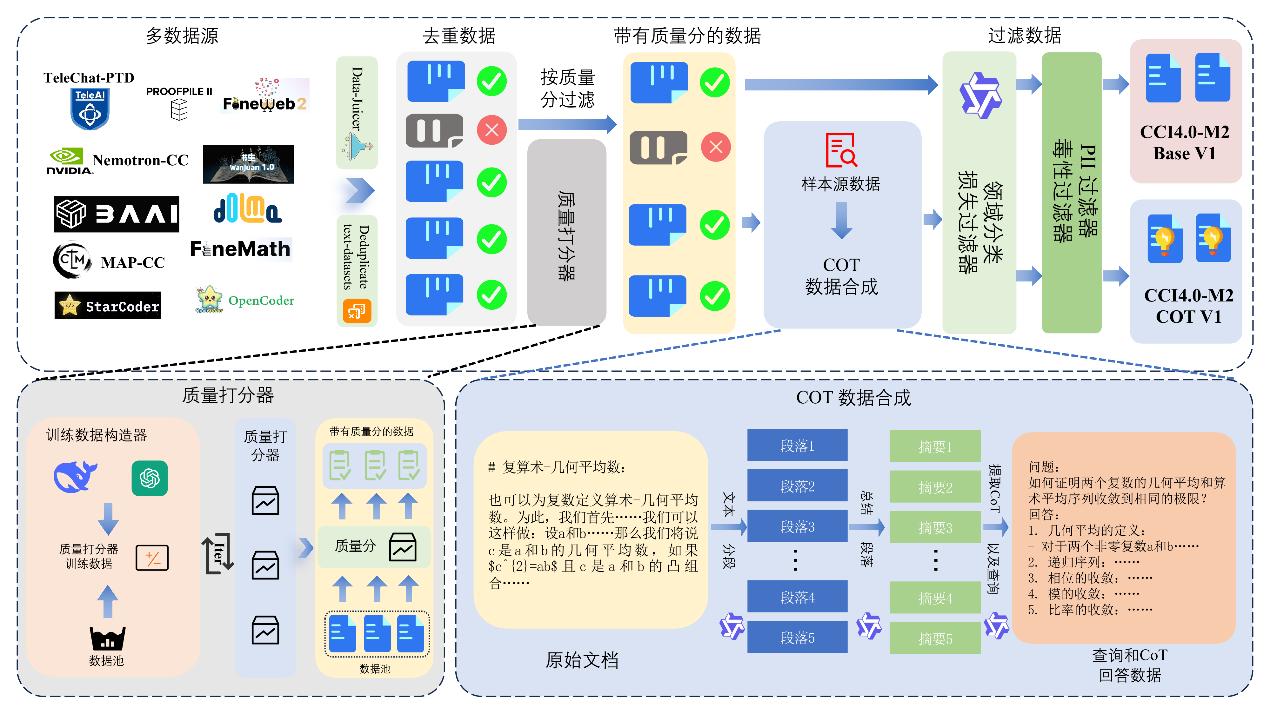
数据集构建流程
二是创新多领域思维链(CoT)数据合成方法,强化模型推理能力。精选网页、数学、代码、论文等多领域高质量数据为种子,利用大模型重建推理逻辑,并结合流畅度过滤,最终合成了当前开源规模最大的420B Tokens思维链推理数据集。实验证明,使用该数据训练的模型在推理任务上困惑度显著降低,有效加速了推理技能的获取。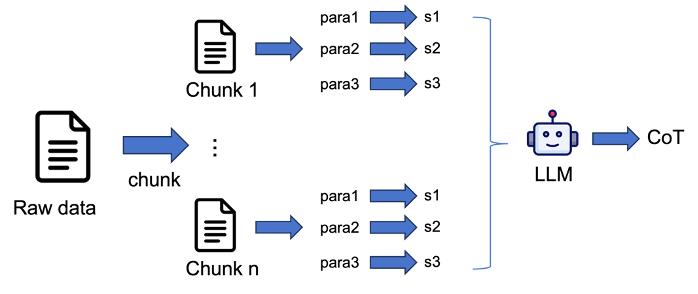
长思维链合成数据构造流程
三是实施全方位安全与隐私过滤,保障数据集落地应用成效。通过融合正则表达式、命名实体识别与毒性分类器等技术,严格剔除隐私及不良内容,确保数据安全合规。基于此构建的CCI系列数据集已获52个国家和地区超600家机构使用,累计下载量达20万次。其中文子集CCI4.0-Zh-HQ在100B tokens训练规模下评测得分达33.57,较第二名高出1.16分,效果稳定超越其他开源中文数据集。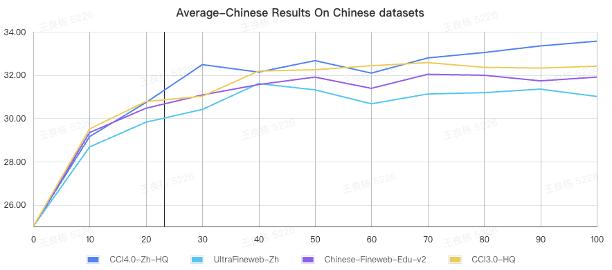
中文高质量子集与同类开源数据集效果对比
三、创新点一是构建多分类器集成的数据质量评估机制。针对单一分类器召回率不足的问题,通过设计差异化提示模板调用多个大模型生成专属分类器,并以集成学习策略融合评分。该机制有效提升了中文高质量数据的筛选规模与精度,夯实了数据质量根基。
二是开创性地将结构化合成技术融入预训练数据构建。为提升模型推理能力,首次通过多源种子筛选、深度语义解析与推理链重构等技术,合成了当前开源最大规模的多领域思维链(CoT)数据集,将长程逻辑推理能力直接注入数据层。
三是整个数据构建流程设计严谨,覆盖数据质量控制的多个关键维度。流程融合多粒度去重、多分类器质量评分、基于生成损失的流畅度过滤、多领域思维链合成以及隐私与毒性清洗五大核心环节,形成端到端的处理链路。通过系统化的实验,对整体流程及各中间模块的有效性进行了充分验证,确保了数据集的可靠性、多样性与安全性。
- 附件: