高质量数据集典型案例 | 全球多口音英语高质量语音数据集
- 2025.10.11
- 来源:国家数据局
- [ 打印 ]
全球多口音英语高质量语音数据集
推荐单位:北京市政务服务和数据管理局申报单位:北京海天瑞声科技股份有限公司
一、背景
全球化发展进程持续推进,语言互通成为促进国际合作交流、科技创新的关键纽带。尽管人工智能语音识别技术已经取得了显著进展,但在面对多口音英语、复杂语言场景时,其准确率和鲁棒性仍存在不足,跨语言技术面临着严峻挑战。为推动国家“一带一路”战略,助力中国企业拓展海外市场,推动学术和科研的交流与发展,加速AI的全球化、多样性与平衡性进程,建设全球多口音英语高质量语音数据集显得尤为迫切。该数据集促进人工智能产业的技术创新,为学术研究提供丰富的资源,推动国际合作,提升我国在全球语音技术领域的影响力和话语权。
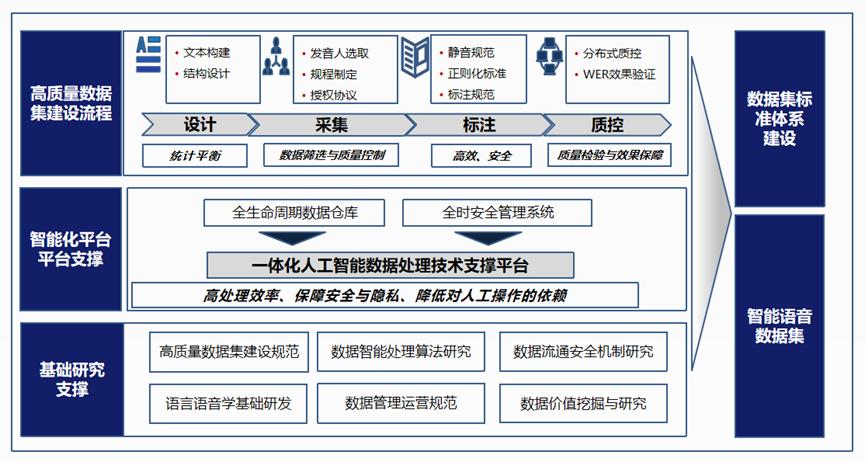
数据集建设框架图
二、方案和成效一是构建了全球多口音英语高质量语音数据集,为通用化、鲁棒性强的语音大模型提供核心数据基座。该数据集是目前全球覆盖范围最广、标注精度最高的多口音英语语音库之一。该数据集融合英语播客音频与专业团队定向采集的65国口音英语语音数据,总时长达124万小时,规模约130 TB。其中英语播客音频包含自然场景下的真实语言数据;专业团队定向采集数据覆盖六大洲英语使用国家,经专家标注后字符准确率超过98%。该数据集覆盖标准英语、地域方言、非母语口音等多样化语音形态,支撑语音识别、语言研究、跨文化交流等领域前沿研究。
二是形成了高质量数据集标准化生产流程,提升高质量数据集规模化供给能力。首先精心设计语料方案,由专业的团队深入到各个国家和地区,根据语料方案收集不同人群的特色英语发音。采集后的数据再由专业团队经过精细标注,然后进行数据质检,保证数据准确率、数据标注准确率,一致性等,最终形成高质量数据集。
三是取得巨大的经济社会效益,推动数据赋能人工智能产业发展。该数据集近三年累计销售375次,产生经济效益3504万元,覆盖商贸流通、智能驾驶、智慧金融、教育科研等应用场景,服务44个全球知名企业。
三、创新点
一是填补全球多口音英语数据集空白,突破单一数据来源的局限性。常用英语语音数据集(如LibriSpeech、TIMIT)90%以上为北美或英国口音,非洲、南亚等地区数据占比不足1%。整合自然场景与专家精标数据,覆盖65国口音英语,收录超过42000种音色,可减少模型对特定语音特征的过拟合,提升复杂环境(如噪音、混合口音)下的表现。
二是数据集生产流程实现工程化、规模化、智能化。通过方案设计、多通道数据采集、智能化数据标注、人机协同数据质检,实现高质量数据集柔性化大规模生产。
三是推动数据集赋能千行百业。在文化旅游、商贸流通、交通行业、智慧金融、教育科研多个领域实际应用,推动人工智能产业发展,推动人工智能数据赋能千行百业。
- 附件: