高质量数据集典型案例 | 端到端语音大模型高质量数据集
- 2025.10.28
- 来源:国家数据局
- [ 打印 ]
端到端语音大模型高质量数据集
推荐单位:青岛市大数据发展管理局申报单位:标贝(青岛)科技有限公司
一、背景
语音大模型在实际应用过程中普遍面临多语言数据稀缺、方言覆盖不足、场景适配能力弱等问题。标贝科技基于“多源采集+生成增强+智能管线”架构体系,构建总时长超130万小时的高质量端到端语音大模型数据集,覆盖全球30余种语种及方言,广泛适配多领域跨场景语音任务。该方案显著提升模型训练与部署效率,端到端训练收敛速度提升40%,模型迭代周期缩短60%,研发成本降低30%,有效推动人工智能技术从实验室阶段向实际应用场景快速转化,构筑显著差异化技术壁垒。
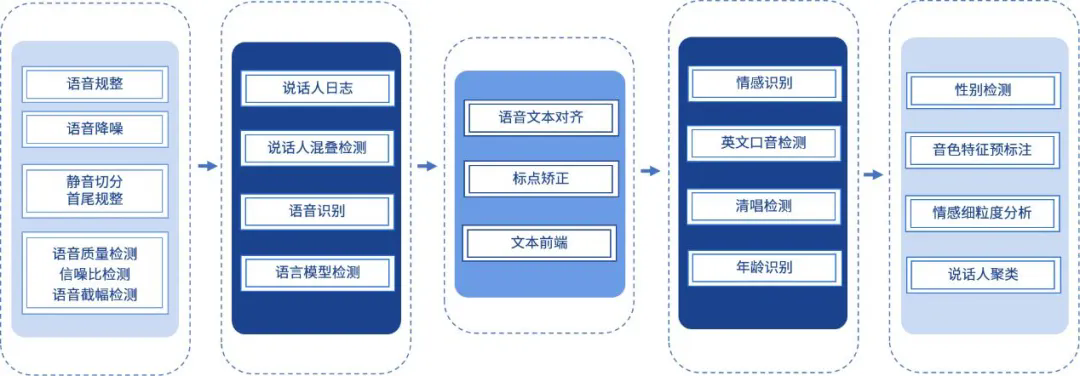
全链路智能语音数据生产管线
二、方案和成效一是构建多源数据融合技术架构,夯实全球化语音交互基座。通过整合公开数据、自建数据、行业数据以及合成数据等多元信息,成功构建超100万小时预训练数据集与30万小时监督微调(SFT)数据集,形成覆盖全球30余种语种及方言的大规模语音语料资源底座,突破传统数据集语言单一局限,为跨模态语音交互提供高覆盖度、强场景化的数据支撑。
二是打造垂直场景深度适配体系,强化模型产业适配能力。聚焦多场景适配共性需求,设计覆盖电商、医疗等垂直领域语料,打造“多语言+多方言+行业场景”三维数据矩阵。依托实时处理架构,实现多样化场景特征动态学习,显著提升模型在复杂业务场景应用中的精准度与鲁棒性,实现数据集与语音识别、合成、翻译等任务快速适配,形成“数据即服务”为核心的高效应用闭环,已成功助力数十家大模型客户完成场景化部署落地,直接经济效益达数千万元。
三是自研端到端智能数据生产管线,驱动数据生产效能跃升。依托自研多模态数据平台,构建覆盖数据采集、清洗、标注、测评、调优全流程的智能化生产管线。通过AI预标注与人工校对协同机制,结合数据增强策略,实现端到端训练收敛速度提升40%,模型迭代周期缩短60%,交付效率提升3倍,研发成本降低30%。
三、创新点
一是多层次数据生产基础设施驱动降本增效。搭建语料设计、合成生产等数据管线及多模态数据平台等基础设施,依托“多源采集+生成增强+智能管线”架构,突破传统数据集场景限制,支持管线灵活配置,全面提升生产效率和资源利用率。
二是端到端闭环训练体系提升模型适配能力。基于全链路闭环体系实现数据输入到模型输出的端到端协同优化。建立迭代反馈机制,形式“训练-验证-优化”闭环,强化复杂场景鲁棒性,构建数据与模型协同优化的良性循环。
三是“基地+API”产业化机制加速技术落地。在青岛、长春、天津等地建立标注基地,同步开放标准化API接口,形成“基地+API”服务模式,实现数据处理、模型训练、部署应用有机衔接,推动多行业语音技术规模化商用落地。
- 附件: